Archive for the ‘Statistics’ Category
Yamal V: … but they pull me back in …
Via Jeff at his blog The Air Vent, in the midst of a post that includes a nontrivial quantity of ALL CAPS and multiple exclamation points (no <blink> tag?), the following statement (since that time stated in a more reasonable tone here):
For some reason EVERY RCS CORRECTION Briffa can conceive of refuses to turn upward to fit the ACTUAL data. This lack of flexibility in the RCS curves is what creates the HS.
I’m not sure why he doesn’t take my post on growth curves at Yamal seriously, but I’ve already explained why this is probably incorrect. The problem is an intermingling of the signal and the noise. As I showed previously, when I constructed an RCS curve using only the recent, living trees from Yamal, because these trees were growing roughly at the same time, and at that during a period of increasing temperatures, estimating a growth curve from them potentially intermingles the climate signal with the geometric growth curve.
One way to look at this is to consider only those trees that ceased growing prior to 1900. I’ve extracted these from the full Yamal set and estimated the regional curve standardization using a 67% spline. Here it is:

Let me be as clear as I can be, there is no sign that I can detect that it is old trees that increase their growth at Yamal (even if identified, this phenomenon would require some hypothesis as to the cause), At Yamal, a portion of the old trees are those that were growing together during a period of climate warming. If you examine the raw ring width, there are a few fossil series that have rapid increases toward the end. If Jeff’s hypothesis were correct, we’d expect these to be the oldest, right? In fact, the seven subfossil samples I identified as having rapidly increasing growth in their later years, six had a wide range of ages from 90 to 180 years (this comes with the caveat that we don’t know the exact pith age).
Furthermore, and as my earlier posts have shown, and as I’ll show again below, using a 67% spline (so that the later part of the regional growth curve bends slightly upward) you still get an increase in the chronology values during the 20th century.
Finally, what of the claim that combining the mean-detrended series demonstrates that the RCS method is invalid? One way we can test this is by first aligning all the ring widths by age (as was done here), observing where the curve of the juvenile grow trend flattens in the majority of trees (eyeballing it at around 175 to 200 years), throwing away the ring widths for the time when every tree was between 1 and 199 years of age (you get essentially the same result if you use 175 years), then realigning by time (year A.D.), and removing the mean. Lets look at the truncated growth curves in time and the mean of these series:

What immediately jumps out at you is that the mean for the most recent century and half is noticeably higher than the earlier part of the millennium. This doesn’t a priori indicate warmer temperature, but as I explained to Jeff here, once again there is the potential for this approach to remove climate signal in the process of detrending. For the most part, the mean following truncation is lower for the non-living trees at Yamal, but for the living 17 trees, the mean is similar or in some cases higher after truncation. Why? At least partially because after truncation the mean of the recent, living trees is of a large portion of the growth occurring during 20th century warming.
So, what do the chronologies look like if we use three different types of detrending? Let’s try constructing an RCS chronology using a 67% spline, negative exponential, and a generalized negative exponential curve:

The top shows the regional curve fit to all the raw Yamal data, the bottom panel zooms in on the part of the chronology since A.D. 1700 (heavy lines are 20 year low pass Butterworth filtered values). The regional curve fit that I think Jeff would endorse (67% spline) to fit his ‘U shape’ hypothesis actually results in slightly higher chronology values following the Little Ice Age, and slightly higher values at the end of the chronology in the mid 1990s.
My point is not to indicate a ‘correct’ method here — that goes well beyond ‘Blog Science’. Rather my point is this: detrending and standardization is one of the most challenging tasks in accurately estimating past low frequency climate variability from tree rings. Divergence is a serious challenge worthy of further study. What I don’t understand, however, is why methods or analyses (mean detrending, identifying growth curves from a small number of simultaneously growing trees) that can be shown to have the potential biases in specific instances that I’ve demonstrated here and in a previous post can still touted by those with a visceral dislike of paleoclimatologists as proof that another method is incorrect. If this debate was a collegial one that might be one thing, but there is nothing collegial — or scientific — about the language and tone from the other side. Too bad. To endorse once again Rob Wilson’s comment from Climate Audit:
“In fact, the fatal flaw in this blog and what keeps it from being a useful tool for the palaeoclimatic and other communities is its persistent and totally unnecessary negative tone and attitude, and the assumption that our intention is faulty and biased, which keeps real discourse from taking place.”
UPDATE: Minor grammar corrections
Briffa on Yamal
Keith Briffa and Tom Melvin have posted an interesting and thorough examination of the Yamal data here:
http://www.cru.uea.ac.uk/cru/people/briffa/yamal2009/
This now supersedes much if not all additional analysis I had considered for possible future posts.
Seeing Red (Noise): Galactic Cosmic Ray Fluxes and Tree Rings
First off, thanks to delayed.oscillator for inviting me to participate. I’m excited to be involved. Secondly, please forgive some of the formatting – I’m still new to this whole blogging thing. And away we go …
A recent paper (Dengel et al), published in the usually rigorous journal New Phytologist purports to show a statistically significant positive correlation between Galactic Cosmic Ray (GCR) fluxes and tree growth of sitka spruce (Picea sitka) from a plantation or managed forest in Scotland. Their hypothesis follows: High GCR fluxes stimulate aerosol nucleation in the atmosphere, leading to higher aerosol concentrations. The increased aerosol concentrations increase scattering of radiation, increasing the ratio of diffuse to direct radiation fluxes. The increased diffuse radiation penetrates more deeply into tree canopies, stimulating photosynthesis and growth.
Others have already shown that links between GCR fluxes and the Earth’s climate are quite dubious. Here we show that the conclusions drawn by the authors of this study are likely based on errors in their statistical analysis and faults in their study design.
The primary evidence in this paper for the GCR/diffuse radiation link to tree growth is tied to two Pearson correlations. One is a correlation between tree growth and March-August total diffuse radiation (n=45, r=+0.29, P=0.05). The second is a correlation between tree growth and GCR fluxes (n=45, r=+0.39, P=0.008). On the surface, both correlations appear to pass the traditionally accepted significance levels of P<=0.05, supporting the authors’ hypothesis.
The authors use a nominal sample size equal to 45, the total number of years in their dataset. This is fine, assuming that the underlying observations represent independent samples, e.g. a ‘white noise’ time series. To test this, we digitized the tree ring growth anomaly time series from the paper and estimated the lag-1 autocorrelation. If each observation were independent, the autocorrelation should be near 0. For this series, the autocorrelation is actually quite high (r=0.484) and significant (P=0.0008), indicating this time series has significant persistence (‘red’). The individual observations are not independent, and the significance of a Pearson correlation with n=45 will be overestimated.
This is easy enough to account for, however:
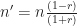
where n=original sample size, r is the autocorrelation of the underlying time series, and n’ is the new (effective) sample size. Plugging into this equation, we find that the sitka spruce tree growth time series has an effective sample size of only 16, instead of 45.
This change will not influence the actual correlation, but it will affect the test statistic used to determine statistical significance. For both correlations, we can recalculate the test statistic and significance level with the new effective sample size of 16:
GCR____ n T Statistic Significance
Original 45 2.7773 0.008
Revised 16 1.5647 0.139
Radiation n T Statistic Significance
Original 45 1.9870 0.050
Revised 16 1.1195 0.281
In both cases, the correlations now do not meet the criteria (P<0.05) to be considered statistically significant.
It is also very clear, from reading the paper, that the researchers were considering many, many possible associations — looking for a statistical correlation between the tree rings and some variable, regardless of whether there was a strong a priori theoretical basis to think there should be. Some of their correlations make sense – boreal summer temperatures concurrent with the growth year, for example, is reasonable since one would expect trees growing in Scotland could (possibly) be sensitive to temperatures during the growing season. Others are more tenuous, as when the authors attempt to correlate tree growth to diffuse radiation from the previous year.
In cases where one is data mining (as in this paper), it is important to guard against significant correlations that may be due simply to the overwhelming number of statistical tests made. Conceptually, it helps to think of the P value as your percent chance of a ‘false positive’, the chance that a statistically significant correlation is due to chance, rather than something meaningful. For most purposes, a P value of 0.05 (a 5% chance of a false positive) or less is considered acceptable. Each time you attempt another test, however, you increase the opportunity for this type of error. So, if two tests are conducted, the chance of a false positive, at a P=0.05 acceptable threshold, is actually 9.75% (assuming independent comparisons). In the case of total diffuse radiation, Dengel et al compared their tree growth time series against total diffuse radiation for each month of the current and previous growth years, a total of 24 tests (70.8% chance of a false positive). This makes it very likely that some of the correlations will be significant due to chance alone.
To adjust for this, researchers may use some flavor of what is called a Bonferroni correction, modifying the original P value to account for multiple comparisons. One simple way to do this is to divide your original acceptable threshold by the number of tests you conduct, increasing the burden of proof to accept a significant result. In the diffuse radiation example (tree growth versus diffuse radiation), that means a P=0.05 should actually be P=0.05/24=0.002. In other words, to have a P value confidence of 0.05, you actually need to meet a much stricter threshold, P=0.002. This burden is not met, either in the original analysis or with the adjusted sample size. The Bonferroni correction leads to less false positives (Type I errors), although it may increase the rate of false negatives (Type II errors).
Aside from not accounting for these features of their data and analysis, there are also some methodological oddities in the study design, where Dengel et al deviate from some standard practices in dendrochronology. First, they do not report many of the standard statistics used to assess the quality of a tree ring chronology-e.g. the mean interseries correlation (the common signal amongst trees) nor the mean sensitivity (a measure of a variable vs. complacent the ring width series). This makes it impossible for a reader to assess how well the trees correlate with each other, and whether the chronology really represents a common signal among the trees rather than simply an assemblage of noise. Second, they appear to use essentially randomly sampled trees from a managed forest. Normally, to find a tree (or set of trees) with a strong climate response researchers target trees where climate is the most limiting factor for growth. This often means trees near their climatic limits, where they may be stressed by temperature, moisture, or even radiation. Plantations or managed forests are typically not limited by these factors, because the goal is to manage growth for some purpose (e.g., timber, wildlife, et). Often this management can be quite intensive, involving fertilizer application, protection from pests, and thinning. Even at a location where tree growth is limited by climate, trees are not simply randomly sampled to try to find a climate signal. In particular, trees that may be influenced by competitive interactions with other trees (shading, etc) are generally avoided, because the signal in the tree rings will not necessarily best represent a response to larger scale climate variability. Randomly sampling trees through an even aged stand, as appears to be done in this study, will likely result in a large-scale signal that is equivocal or, worse, misleading. This is evidenced clearly by Figure 2 in the paper, where the authors attempted (largely unsuccessfully) to correlate tree growth against precipitation, temperature, and vapor pressure deficit. Dengel et al also use very short time series (only 45 years of growth), truncate the trees such that the juvenile growth is partially removed, and appear to use a relatively stiff spline in their detrending (potentially problematic in trees that may have experienced growth changes related to stand dynamics).
The criticisms I have made are not particularly nuanced or obscure, and are largely standard practice in climatology and dendrochronology. The lack of adherence to these practices likely led Dengel et al astray. I largely suspect their results will not be reproducible in other studies with a more typical design and analysis, but time will tell.
Yamal IV: Growth Curves and Sample Size
Via Deep Climate, I found this post by Jeff Id at The Air Vent. Comments there and elsewhere lead me to believe there is some confusion about the related question of regional curve standardization and the reason for the importance of sample size in dendrochronology — dendroclimatology in particular — and while this post is only an indirect commentary on Jeff Id’s post, hopefully it will be more broadly useful or stimulate some interesting technical discussion. For more information on regional curve standardization, this book chapter [PDF] is currently your best bet.
Jeff Id fits two separate exponential growth curves to the most recent 12 trees in the Yamal chronology and to the full Yamal series, and notes that they are different. Let’s emulate this here. Let me note first of all that this is an emulation — the published Yamal series uses a time-varying spline fit that I haven’t integrated in my own code.

What I’ve done is align the full Yamal set (blue) and the most recent 12 ring width series (red) by age, assuming no pith offset (that is, assuming the innermost ring in the core or cross section was the innermost ring in the tree). The heavy lines are the mean regional curves. The black line is the Khadyta River mean regional curve.
There are few interesting features, some of them I believe are noted by Jeff in his post. The more recent Yamal trees had a somewhat lower growth rate when they were young than the average of the full set of living and subfossil trees; however, it is not at all out of the range of the full Yamal population. The regional curve for just these twelve is therefore lower than that of the regional curve for the full population. Another feature to note is that the red line (the regional curve for the 12 trees alone) rises at 100 years of age and again near 300 years of age, since these represent the ages of the most recent wider ring widths of several of the individual samples in this small set. Finally, note that the Khadyta River trees as a whole are relatively young, and their growth falls for the most part lower than the regional curves for the Yamal full and recent subsets.
UPDATE: I’m adding here the spline curve fits

So what is the consequence of performing a separate RCS on the recent Yamal series only vs. the full Yamal set?

The 12-series only chronology is somewhat noisier overall, since it also excludes 5 other tree ring series that come into the second half of the 20th century but not all the way into the 1990s. The influence of sample size on the chronology variance can also be seen in the 1600s, probably, when the year-to-year variability is reproduced but the small number of series (prior to 1660 or so, there are only 3 cores) influences the variance. The influence of the different regional curves — shown above — is more difficult to detect, since it is intermingled with the influence of the loss of the other 5 cores, but slightly higher levels in the 12-tree only chronology in the 1600s and parts of the 1700s might reflect it. The most notable difference is therefore perhaps that the recent-tree only chronology is slightly lower than the full Yamal chronology starting in the early 1980s.
So what is going on? In fact, you are witnessing the importance of overall sample size in the specific case of Regional Curve Standardization. It is important to understand the importance of sample replication for two different (but of course complementary) purposes in dendrochronology, specifically when applying Regional Curve Standardization: [1] Adequate sample replication overall so as to accurately estimate the ‘true’ regional growth curve, and [2] sample replication through time adequate to estimate the transient climate signal. Remember that the goal of regional curve standardization is to remove a common age-related growth trend while preserving low frequency climate variability — to have any hope of estimating this you need a large number of trees whose actual period of growth was well-distributed over time. The reason for this is that you need to avoid intermingling your climate signal of interest with your age-related growth trend. You can imagine an age-related growth trend estimated by trees of more or less the same age that grew more or less at the same time could intermingle the time-related environmental signals with the age-related geometric growth patterns. On the face of it then, Yamal is a good candidate for RCS since it has a large number of total trees whose actual time of growth is well-distributed over the length of the chronology. Isolating the 12 most recent trees, however, runs the risk of intermingling recent patterns of temperature variability with the trees’ common growth signal. The ‘regional curve’ from just these twelve trees is quite unlikely to be very representative of some significant fraction of the mean regional growth pattern associated with tree age.
The full Yamal regional growth curve is therefore likely to be a much better estimate of the ‘true’ regional growth curve common to trees from the region than a growth curve from a small number of trees growing over a period of anthropogenic climate change, because the climate signal of interest is a common feature of the growth of many of the trees. The lower chronology values in the recent-only chronology is red above is a consequence of at least part of the temperature signal being subtracted because it is intermingled when the regional curve is calculated over only a few trees growing, at the end of their life, in a warming world. Jeff’s post is a little hard to parse in places (for one thing, he keeps referring to ‘climatology’, but I think he mean ‘climatologists’ or the ‘climatology community’), but reading carefully, I think he might recognize this as a potential problem.
Now, the other important part of having multiple samples from the same site is maximize the signal to noise ratio (for our purposes, the signal is climate) at any given time. Dendrochronologists have ways of traditionally estimated whether their chronology is sufficiently well-replicated and contains a common signal, including the Expressed Population Signal or Subsample Signal Strength. Using 20 year windows with 10 years of overlap, the Expressed Population Signal for the 12-series only RCS chronology is consistently above the (arbitrary but historical) 0.85 level back to the 18th century (and, indeed, most of the way back to the earlier parts of the chronology before sample size is reduced to a few cores). For 10 year windows with a 5 year overlap (not something I would consider particularly stable, but it allows us to look at very small slice of time), the EPS exceeds 0.85 from at least 1990 back to beginning of the chronology with only two decades in the 19th and 18th centuries with low interseries correlation. Note that these windows are shorter than we normally use.
My take home message is this and it is intended to be general: it is important to understand the two complementary parts of the importance of samples size in developing RCS chronologies for climate reconstruction. Lots of ring width series are necessary to develop an accurate regional curve. The number of chronologies needed at any given point in time to capture the transient climate signal can be estimated using EPS. Strong average interseries correlation between cores can mean that even relative few trees collectively capture a significant portion — again, as estimated from established metrics — of the climate variance and allow for adequate signal to noise ratios in the mean chronology. Replication gives us increased confidence in the value of the mean chronology, but a strong common signal is an important part of the equation.
Yamal III: Summary and Update
A fair number of people have been visiting this humble blog in the last few days, presumably not for my excellent tips on where to find the best huevos rancheros in the world. My previous posts on Yamal are long and perhaps technical in places, so I wanted to provide a quick summary.
in Yamal I, I emulated the modifications of the Yamal chronology by Steve McIntyre. As I noted in that post:
Adding the Khadyta River series reduces the the level of the chronology though the 1970s and 1980s and into the early 1990s, when those data end. But if one includes both data sets, the series terminates similarly to the original Yamal chronology, of course (because the last few years are only present in the modern trees from Yamal). These changes are potentially important, and the actual scientific questions are interesting
I also noted that the manner in which the series are low pass filtered can change the impression of the impact of these changes. Smoothing and filtering series — particularly dealing with end points — is a complicated issue, so care is always necessary when designing, deploying, and subsequently interpreting smoothed series.
In doing the emulation, I noted that there are differences in the archived Yamal, McIntyre emulation, and my own. These probably arise due to the different curve fitting techniques (time varying spline for Yamal, nonlinear least squares for McIntyre’s R code, and standard spline or Supersmoother fitting for my emulation). In terms of identifying relative differences due to adding the Khadyta River data, though, these don’t seem to matter too much. Apparently, McIntyre noted that his RCS routine created a greater rise than the archived Yamal chronology (again, this is probably differences in curve fitting, if I had to guess), but I can’t locate the statement now.
I also see, via Deep Climate, that McIntyre has posted graphs showing the chronology from the full data set (including the complete set of trees from Yamal and Khadyta River). We seem to differ on showing the period from 1991 to 1996, apparently — I think if you are going to make rather strong statements about using all the data, you should use all the data, but I don’t expect us to agree on this.
So, more interesting perhaps is my second post, Yamal II, where I looked at the raw data from Yamal and Khadyta River. Here, I concluded:
Khadyta River does display the divergence problem, in that it ceases to track temperatures as it did from 1883 to the 1960s.
and, finally:
Relatively little more can be said about the specific case of Yamal at this point — I’ll leave that to the scientists working in this part of the world — but even my quick review of these data here shows that including Khadyta River raw data in the Yamal chronology does not result in a more accurate nor precise understanding of past temperatures in the region. This isn’t to say that some time in the past that Yamal didn’t experience divergence (this after all is a large part of the concern about divergence), but we can clearly see that Khadyta River does exhibit modern divergence.
That’s where I stand now, and I’m not sure what further insights will come from solely the data at hand. However, reading blog posts about this topic, I’ve become aware that there persist misunderstandings in how field and lab dendrochronology is actually done. So, hopefully there will a post about this from me in the near future.
Yamal Emulation II: Divergence
As I mentioned in my previous post, the Khadyta River chronology appears to suffer from the classic signs of what dendrochronologists have come to call ‘the divergence problem‘. Before I continue, however, I should emphasize a few points.
[1] I didn’t collect the Khadyta River chronology. Neither did Steve McIntyre. The problem with treating tree ring chronologies as nothing more than received time series downloaded from the internet to be manipulated in various ways is that the context of the original investigators can be lost. Moreover, there are several subdisciplines within dendrochronology that collect tree ring data for different reasons, and in their fieldwork emphasize different site or individual tree characteristics during sampling.
[2] In any case, the concept of what comprises a single ‘site’ is ill defined (Wikipedia covers this in the context of archaeology). There is no hard-and-fast rule for how to geographically delimit which group of individual trees belong to a given chronology site.
Let’s return to Yamal and Khadyta. Remember that adding the Khadyta raw data to that from Yamal gives us the following situation (zooming in on the last century and a half now):

What becomes clear immediately is that the two chronologies diverge in approximately the early 1970s. Why does this occur?
We can look at the raw data from each site separately. First, I’ll graph the standardized raw data (to account for differences in tree size and mean growth rate) and their mean from Khadyta:

Again, what jumps out here is that the trees at this size show a decrease in growth in the late 1960s and early 1970s. The step change that the mean takes jumps out at me immediately.
Lets look at the same type of plot for the Yamal data:

Here, the persistent low growth years seen at Khadyta after 1970 are not present in the majority of trees (although, interestingly, perhaps in a few of them). As a consequence, the mean raw value continues to climb through the 1980s and 1990s.
We can now look at the two mean raw value time series together, as well as compare them to the gridded temperature data from the region. For this purpose, I’ve extracted summer (JJA) temperature for the grid box [65-70N, 65-70E] from CRUTEM3— a bit crude, but for the comparison to the raw mean data, it will serve our purpose:

Considered individually, and remember here with no detrending, both mean time series track each other — and the gridded summer temperature — well at both low and high frequencies. The two mean tree ring series diverge starting in the 1960s. Both track years with lower temperatures in the late 1950s and 1960s, but by the 1970s, Khadyta fails to mirror regional warming in the gridded summer temperature. Yamal continues to track increasing temperatures from the 1970s through the 1990s.
This quick-and-dirty analysis emphasizes a few points. Khadyta River does display the divergence problem, in that it ceases to track temperatures as it did from 1883 to the 1960s. At first glance, in this case, the divergence doesn’t seem to be related to detrending [PDF], and really does seem to reflect a decline in growth in the most recent decades. Second, adding Khadyta River data to Yamal is unlikely to reflect temperatures in the region more accurately.
I want to emphasize that neither Yamal nor Khadyta River are ‘the problem’ — divergence is the problem, and for this reason is a major [PDF] area of focus in dendrochronology. Relatively little more can be said about the specific case of Yamal at this point — I’ll leave that to the scientists working in this part of the world — but even my quick review of these data here shows that including Khadyta River raw data in the Yamal chronology does not result in a more accurate nor precise understanding of past temperatures in the region. This isn’t to say that some time in the past that Yamal didn’t experience divergence (this after all is a large part of the concern about divergence), but we can clearly see that Khadyta River does exhibit modern divergence.
A very interesting paper with relevance to this issue appears to be in press in Global Change Biology:
Esper, J., Frank, D., Buntgen, U., Verstege, A., Hantemirov, R., and Kirdyanov, A. (2009). Trends and uncertainties in Siberian indicators of 20th century warming. Global Change Biology, in press [subscription wall]
Check it out if you can.
Yamal Emulation I
UPDATE: Not following? Try Yamal III, a summary and update.
Steve McIntyre has once again stirred the hornet’s nest of online climate change denial with a hasty modification of the Yamal tree ring data published by Keith Briffa and colleagues in 2008 as part of a paper in Philosphical Transactions of the Royal Society (Phil. Trans. R. Soc. B (2008) 363, 2271–2284). Normally, I ignore McIntyre’s blog because of the juvenile name calling, repetitive nonsense, and the general misunderstanding of huge swaths of proxy paleoclimatology. However, I knew when Roger Pielke Jr. jumped in with support for his collaborator, it merited some attention [insert smiley face emoticon here].
Here, I’m actually interested in the data and the science. The first thing was to emulate the steps that McIntyre had performed (an audit, if you will), leaving aside for the moment whether they are even proper steps from a data point-of-view. McIntyre has rolled his own Regional Curve Standardization code in R, strangely eschewing the freely available software used by dendrochronologists, so I wanted first to ensure there was no significant error in his approach.
I downloaded the original Yamal data from here, and the Khadyta from the ITRDB here. I used ARSTAN to first emulate the original chronology used in Briffa et al. 2008. My regional curve standardized chronology differed slightly from the published version available here, probably because Briffa et al. 2008 used a time-varying spline for the regional curve, but the essential features, including the increasing values in the 20th century, are essentially the same. All these data and programs are publicly available. You can check these results for yourself.
I then added the Khadyta River raw data (which shows evidence of the ‘divergence problem‘) to the set of raw Yamal data, and recalculated the master chronology using regional curve standardization (because I am positive that McIntyre would insist on using all the data). Again, I am not yet addressing here whether it is [1] appropriate to add these data or [2] appropriate to not also add other or different data. Here is a comparison of the two versions:

Devastating, I know.
The real differences of course arise at the end, where the modern, relatively short series from Khadyta influence the final chronology.

Adding the Khadyta River series reduces the the level of the chronology though the 1970s and 1980s and into the early 1990s, when those data end. But if one includes both data sets, the series terminates similarly to the original Yamal chronology, of course (because the last few years are only present in the modern trees from Yamal). These changes are potentially important, and the actual scientific questions are interesting (as opposed to the political expedience of selecting certain findings to attack one’s political enemies). But the actual impact on the chronology is still far less than being implied by non-scientist partisans on one side. Why is that?
Part of the difference appears to be McIntyre’s use of a 21 year Gaussian low pass filter. The issues of how to smooth data series to avoid misleading end effects is not a trivial one. I can replicate the strong upturn in the modern era in McIntyre’s graph by using reflected end points. This creates the illusion of a massively unprecedented rise in ring width:

But as the close up view shows, one influence of the filter is such that it helps create the appearance of a massive rise, when annual values in mid-century are actually similar to those in the late 20th century.
There are actually interesting scientific questions (as opposed to the utterly uninteresting partisan griping) at play here that deal with the ‘divergence problem‘. I’ll address those in the next post.
UPDATE: See also here, here, here, and especially here, where RealClimate commentor Tom P has done several sensitivity tests and emulations with these data.
UPDATE [10/06/09]: I should emphasize that this isn’t a comparison of standard RCS software vs. McIntyre’s home grown code. I might fire up R and do that comparison at some point, but I expect any differences to be minor.
UPDATE [10/09/10]: In case it still isn’t clear, my point about smoothing is not that there is anything wrong per se with a 21 point Gaussian filter using reflected endpoints. Rather, I’m pointing out one of the reasons that the initial graphs, posted at Climate Audit but that I first saw at Deltoid, convey such a dramatic rise in the last several years compared to mid-century is the behavior of this particular method.

{kind=link}
You must be logged in to post a comment.